



(1) Overview
Introduction
Artificial Neural Networks (ANNs) have proven their reliability in solving complex systems for pattern recognition and multivariate regression [, ]. Although the backpropagation technique was developed 40 years back [], the interest in ANNs increased dramatically in the last decade because of the advances in hardware and the needs of artificial intelligence applications in handheld devices. Most of the uses of ANNs nowadays are for pattern recognition, either for handwriting recognition, image recognition, or more advanced applications like Self-driving cars []. However, the regression analysis of ANNs plays the most important role in scientific research especially for economic, biological, and environmental research (e.g. [, , ]). The primary function of the ANN software packages is to perform training, validating, and testing the network, then use the trained network in prediction/recognition of missing features/patterns. Most of the commercial packages dealt with the ANNs as a black box, not allowing the user to analyze/modify the resulted weights and biases, or to make some studies on the effects of some input features on output features, especially when the feature is categorical. In scientific research, after finding the suitable ANN, the researchers need to analyze the inputs/outputs features and their relations to each other and to plot these in order to discuss them in their publications, however, most of the existing packages just perform the training and prediction roles, leaving the analysis and studies for the researcher.
The aim of this work was to develop an open sourced ANN package that can be used easily by researchers to train the ANN, find its optimal structure, reuse the trained ANN in prediction, and plots all the possible relationships between inputs and outputs in a publication quality charts.
Implementation and architecture
The program contains four main classes; the Study Class, the NeuralNetwork Class, Data Class, and PlotNet Class, Figure 1. The main class is the Study Class where we can select one of five running modes;
- To perform a full run, where the whole data is used for training the network (no partitioning).
- To perform a cross validation, where the given data will be partitioned into three partitions; about 70% for training, 20% for validation, and 10% for testing. The mentioned partitioning ratios are the defaults, but they can be specified by the user. In this mode, we start by the training data set, but at the end of each epoch, we check the errors of the validation dataset, if the error of the latter starts to increase instead of decrease, the training will stop as it will be considered an evidence of overfitting. This is the default purpose.
- To perform a progressive validation, where the given data will be partitioned as specified before. In this mode, we start by the validation dataset, from which we specify the stopping epoch, then we launch the training dataset for maximum epochs equals to double the validation epochs. This mode was proved to eliminate overfitting.
- To perform an optimization run, which is similar to the validation run, but involves searching for the best ANN structure and best activation functions before starts training.
- To perform a query, i.e. to predict output features depending on saved ANNs.
The architecture and workflow of the program.
In the initiation of the Study class, the Data Class is called to manipulate the data and to specify the suitable ANN structure; then the NeuralNetwork Class is called to construct the ANN accordingly.
The Data Class automatically analyses the given data, determines the type of each variable (either numeric or categorical), then it normalizes the data to be ready for analysis by the NeuralNetwork Class. Additionally, in the case of querying predictions of features, the Data Class is used to check the suitability of each data line, and to normalize or denormalizes outputs. This class contains a sub class Variable, which uses mini-max normalization for numeric features, and 1-of-C dummy encoding for categorical features []. Additionally, it provides basic statistics of each feature/variable depending on its type; for numeric features, it calculates minimum, maximum, average, variance, and standard deviation, while for the categorical features, it provides, the members of the category and the percent each one as it appears in the given data. The program allows optional variables’ titles as they are placed at the data headers in one or two lines; the first line is for full-captions and the second for brief-captions which are used in graphs.
The NeuralNetwork Class creates and solves neural networks. While creation, the structure of the network is specified according to the normalized data. To ensure fast learning rate, the ANN weights are initialized randomly within the range of  as suggested by [, ]. The class uses sequential (online) learning mode to manipulate the data as it is more likely to escape from local-minima than the batch mode [, ]. This means that the errors are updated after manipulating each data line, not after manipulating the whole dataset as in batch mode. The NeuralNetwork Class consists of the Layer sub-class which specified the layer type (input, hidden, or output), and manages the child neurons by their sub class. The Neuron Class initiate neurons, each with its specific weight, bias, and activation function. It also calculates the deltas and the cost function of each neuron. This helps in customizing neurons according to variables types. As we described earlier, the training is triggered from the Study Class depending on the mode of the class. In the full run, validation run, and optimization run the ANN training starts by feed forward operation, where the inputs of each neuron are calculated as the summation of the product of weights and outputs of the previous layer, while the outputs of the neurons are calculated by smashing the inputs using the activation function. The default activation function is the sigmoid function. However, the program supports twelve different activation functions, Table 1. After reaching the output layer, the cost function for each neuron is calculated as 0.5 (Neuron target-Neuron output)2 then we sum the cost of all output neurons to find the cost that will be used in the backpropagation process.
as suggested by [, ]. The class uses sequential (online) learning mode to manipulate the data as it is more likely to escape from local-minima than the batch mode [, ]. This means that the errors are updated after manipulating each data line, not after manipulating the whole dataset as in batch mode. The NeuralNetwork Class consists of the Layer sub-class which specified the layer type (input, hidden, or output), and manages the child neurons by their sub class. The Neuron Class initiate neurons, each with its specific weight, bias, and activation function. It also calculates the deltas and the cost function of each neuron. This helps in customizing neurons according to variables types. As we described earlier, the training is triggered from the Study Class depending on the mode of the class. In the full run, validation run, and optimization run the ANN training starts by feed forward operation, where the inputs of each neuron are calculated as the summation of the product of weights and outputs of the previous layer, while the outputs of the neurons are calculated by smashing the inputs using the activation function. The default activation function is the sigmoid function. However, the program supports twelve different activation functions, Table 1. After reaching the output layer, the cost function for each neuron is calculated as 0.5 (Neuron target-Neuron output)2 then we sum the cost of all output neurons to find the cost that will be used in the backpropagation process.
Table 1
Different activation functions available in the NeuroCharter program.
| Name | Formula | Derivative |
|---|---|---|
| Sigmoid |

|

|
| Softmax |

|

|
| Binary |

|

|
| Soft sign |
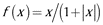
|

|
| Bent identity |

|

|
| Gaussian |

|

|
| Tanh |

|

|
| Linear |

|

|
| Arctan |

|

|
| Sinusoid |

|

|
| Soft plus |

|

|
| Sinc |
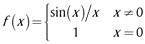
|

|
One of the features of the program is to plot the ANN in an informative way; showing the weights and biases with line thicknesses that reflect their values and sign, Figure 2, The PlotNet Class uses the Matplotlib library to draw the network through three sub classes. The core algorithm of ANN plotting is based on Milo et al. []. The main class is responsible for specifying the outlines of the network, and the locations of the child components like layers and neurons. The PlotLayer Class draws the synapsis (lines) with thicknesses and colors that reflect the magnitude and sign of the weight where the heavier thickness of the lines imitates higher magnitudes of weights, and the line colors reflect the weight’s sign (blue and red for positive and negative). PlotLayer Class also initiates Neurons and biases, sending their information to PlotNeuron and PlotBias classes that are responsible for drawing either. The main difference between the two child classes that the latter is in charge of drawing the bias and its synapses lines, while the former is in charge of drawing the neuron only, while the weights are drawn by the PlotLayer Class as mentioned.
A full ANN diagram showing weights and biases. The heavier thickness of the lines reflects higher magnitudes of weights; the line colors reflect the weight’s sign (blue and red for positive and negative). Categorical features’ neurons are lighter in color for normalized layout.
Program outputs
The main output of NeuroCharter is a set of hi-res charts representing almost all that researchers need in publishing their papers. However, NeuroCharter outputs detailed text outputs in CSV formats to help researchers to analyze the results their way. Furthermore, while training, a step by step progress of the program is printed to the console along with execution times which helps to diagnose errors if any. Some of the outputs of NeuroCharter are the following, detailed outputs description in the tutorial file listed at the ‘Quality control’ section of this paper:
- ‘NrCh_NormData_????.csv’ a list of inputs and output data in normalized form., where the???? is an encrypted timestamp of the execution time.
- ‘NrCh_Weights_????.csv’ a list of weights and biases of the network after training.
- ‘NrCh_Outputs_????.txt’ a continuous file handling all the studied ANNs information including structure, weights, activation functions, and other variables.
- ‘NrCh_StoredANN_????.nsr’ A Neural Structured Repository (*.nsr) file (encrypted) where the whole study is saved including the ANN structure, weights, and data limits, thus it can be recalled by NeuroCharter for later predictions.
- ‘NrCh_Clouds_????.csv’ a set of given vs. predicted data by the ANN.
- ‘DataFile_Output.txt’ a list of predicted values of the output features in de-normalized format, where ‘DataFile’ is the name of the original data file name.
-
‘NrCh_OutputCharts_????.pdf’ all the output charts from NeuroCharter. where the ‘?’ characters are replaced by the current date and time where the study performed. The pdf file basically consists of 6 pages, in addition to 1 page per output variable. The basic pages are:
- The cost function development during different stages (training, validation, and testing) Figure 3
- The full ANN structure diagram, Figure 2.
- A brief ANN structure where the categorical neurons of each variable are consolidated to one neuron for a better understanding of variables contribution, Figure 4.
- The relative importance of inputs to outputs, one bar chart with +ve and –ve contributions of each variable, and one pie chart for each output variable, Figure 5.
- Prediction function and data cloud, the predicted curve vs. the original data for each output variable, Figure 6.
- Real vs. predicted data, plotting given data vs. predictions on 45° line curve, Figure 7.
- Effect of each input feature on all output features, one page per output feature. Within each page, there is one chart per output feature. Each chart contains three curves, at 25, 50, 75% of data. Figure 8 and Figure 9 for numeric and categorical input features respectively.
Cost development through deferent stages.
Brief ANN diagram showing weights and biases. Lines and colors are similar to the full ANN diagram, except that categorical features’ neurons are heavier in color to reflect consolidation.
Sample relative importance charts.
Prediction function and data cloud.
Given vs. predicted data on 45-degree line.
Sample relational charts of numeric input feature.
Sample relational charts of categorical input feature.
Quality control
To understand how the program works, we provide some examples below. However, we provided full docstrings for all functions and classes in addition to informative comments before the key routines.
Program tutorial
A simple tutorial is located at the GIT page, here: https://goo.gl/TGop2p. Please read it before proceeding to the next examples.
Example for creating and training an ANN
If you have data in CSV file format (say its name is dataNT.csv), to start a Study that involves normalizing data, building an ANN, train it, and visualize results in pdf format, so please consider adding the following code at the end of the program, or you can import the program as is, and add this code after the import statement (the program and the testing file should be in the same folder, please refer to the instructions at the simple tutorial above):
from NeuroCharter import Study
The basic line code that can do this job with the default parameters is:
Study(‘dataNT.csv’, num_outputs=4)
While for more control of the study’s parameters, the user can specify more parameters’ values such as the following:
Study(‘dataNT.csv’, ‘cross validation’,
num_outputs=4, data_partition=(65, 15),
tolerance=0.001, learning_rate=0.4,
maximum_epochs=3000, adapt_learn
ing_rate=False, annealing_value=2000,
display_graph_windows=False, display_
graph_pdf=True, data_file_has_titles=True,
data_file_has_brief_titles=True)
Example for using trained ANN for prediction
If you have data in csv file format (say its name is QueryN.csv), to start a Study that involves normalizing data, retrieving the ANN, and predict the output features, so please consider adding the following code at the end of the program, or you can import the program as is, and add this code after the import statement: either to simple query:
Study(‘QueryN.csv’, ‘query’, previous_study_
data_file=‘NrChNet.nsr’)
Or, alternatively with advanced query:
Study(purpose= “advanced query”, Previous_study_
data_file= ‘NrChNet.nsr’,
start_time=time.time(),input_parameters_
suggested_values= ([10, 45, 5], 7.5, (0.5,
0.8), (‘A’, ‘C’)))
Validation of results
The results of the program were validated by comparing to the results of Statistica v13 academic edition running the same problems. All of the tested cases match very well with the results of NeuroCharter. However, Statistica deals only with one type of outputs at a time (either numeric or categorical through the regression and classification modules respectively), while the proposed software can deal with both types at the same time. The results of Statistica show faster performance and a small increase in the accuracy measures like the correlation coefficient, which may be attributed to that they use more advanced algorithms in training than that we employed in this software. However, the sensitivity analysis of the variables and the predictions match very well with our software.
(2) Availability
Operating system
Windows, (Tested only on Windows 10 64bits).
Programming language
The program was programmed in Python 2.7.12. It is not suitable to run with Python 3.* without modifications.
Additional system requirements
No special requirements of hardware, the faster the better.
Dependencies
The program requires Microsoft Windows OS and Adobe Acrobat to be installed. Additionally, as the program has no graphical user interface in its current version, it requires Jet Brains PyCharm and Anaconda (for python 2.7.*) to be preinstalled as well. All the dependencies and the requirements installation steps are listed in the attached tutorial (https://goo.gl/TGop2p). The program requires some of the built-in libraries (collections, copy, CSV, datetime, math, itertools, random, shelve, subprocess, and time). Additionally, it requires the following external libraries to be installed: matplotlib 1.5.1, prettytable 0.72, reportlab 2.7, scipy 0.19, and numpy 1.11.0. (Please refer to the installation tutorial for details.)
List of contributors
Authors only.
Software location
Archive: FigShare
- Name: NeuroCharter, software for artificial neural networks
- Persistent identifier: DOI: 10.6084/m9.figshare.5293453
- License: MIT
- Publisher: Mohammad Elnesr
- Version published: 1.0.79
- Date published: 08-08-17
Code repository: GitHub
- Name: NeuroCharter
- Identifier:https://github.com/drnesr/NeuroCharter
- Licence: MIT
- Date published: 08/08/17
Language
English.
(3) Reuse potential
NeuroCharter can be used to perform regression analysis for systems in many fields including but not limited to environmental systems, bio systems, soil and water systems.
If a researcher has any system of independent inputs, and their corresponding outputs, this software can normalize the data, build an artificial neural network, train it, and save it for future use in querying regression data. The researcher can benefit from the publication-quality graphs the program provides, in addition to the detailed reports about the trained network. Through the saved network, the program can easily predict the output features of any query dataset. The program is free-to-use according to the MIT license agreement. Contributions to add more features to NeuroCharter are most welcomed. Technical support to the software is provided in a limited scope, by direct email to the corresponding author, or to the GIT repository.
Important: To reuse this software easily, please follow the instructions at the tutorial file mentioned above.