



(1) Overview
Introduction
The homogeneity test is a statistical test method that checks if two (or more) datasets came from the same distribution or not. In the time series, the homogeneity test is applied to detect one (or more) change-point/breakpoint in the series. This breakpoint occurs when the dataset changes its distribution. This detection of distribution change makes the homogeneity test an essential test in statistical analysis. In fact, homogeneity is one of the most important assumptions in time series analysis. For example, predicting financial time series, analysis or forecasting of historical meteorological data, etc. If non-homogeneity is undetected, selection of the best model could be influenced by the selected sample. There are several tests available to check homogeneity viz. Pettitt Test, Standard Normal Homogeneity Test (SNHT), Buishand’s Test, etc. These tests can be performed using different commercial software packages like XLSTAT []. Different programming languages like R, Matlab, etc. have different packages or scripts for those tests [, ]. However, a python based single package to perform the most widely used homogeneity tests will save time and bring diversity into the analysis. Because Python is one of the most widely used tool used by data scientists. A large number of data analysis and research tools are also developed using Python. However, till now, there is no Python package available for the homogeneity test. pyHomogeneity package will fill this gap.
Implementation and architecture
pyHomogeneity is a pure Python implementation for the homogeneity test. Two core python packages named NumPy [] and SciPy [] are used to build pyHomogeneity. The vectorization approach is used instead of the traditional for loop to improve calculation speed. This package can perform six different homogeneity tests (three unique tests with four variants of Buishand’s test), which are widely used in time series analysis. Available tests in the pyHomogeneity package are briefly discussed below:
Pettitt Test
In 1979, A. N. Pettitt proposed a change-point detection test based on Mann-Whitney two-sample test []. For a continuous dataset, Pettitt statistic U(k) can be calculated using the equation below:

Where, r1, r2, r3,………,rk are the ranks of the k observations x1, x2, x3,……, xk in the complete sample of n observations and U(k) is calculated for every k = 1,2,3,……,n. The maximum of absolute values of  refers to the probable change point at k-th data. The approximate probability for a two-sided test is given by
refers to the probable change point at k-th data. The approximate probability for a two-sided test is given by
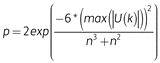
Where, the approximate probability is good for p ≤ 0.5 []. The probability or critical values for the test statistic also can be estimated using Monte Carlo simulation.
Standard Normal Homogeneity Test (SNHT)
Standard Normal Homogeneity Test (SNHT) is based on the Ratio Test Method []. This method is best suitable to detect non-homogeneity near the beginning and end of the series []. The T(k) is calculated by comparing the mean of the first k data of the record with the last n-k data as follows:

Where,





The T(k) reaches its maximum value when a breakpoint is detected at the data point K. The test statistic T0 is defined as:

The null hypothesis will be rejected if T0 is above a certain level, which is estimated using Monte Carlo simulation.
Buishand’s Test
In 1982, Buishand proposed a homogeneity test method based on adjusted partial sums []. The test statistic is given below:

Where,

The maximum of the absolute values of  is referred to as the probable change point at k-th data.
is referred to as the probable change point at k-th data.
Buishand proposed four ways to check the sensitivity of this homogeneity test. These are:
Q test
In this method, Q is calculated using the equation given below and critical values for the test statistic are obtained from the table by Buishand [] or using Monte Carlo simulation.

Range test
In this method, Range R is calculated using the equation below. Critical values for the test statistic can be derived from the table by Buishand [] or using Monte Carlo simulation.

Likelihood Ratio test
The test statistic V(k) is calculated from the equation below []. Critical values for the test statistic are derived from the Monte Carlo simulation.

U Test
According to Buishand, U statistic is a robust test and good for detecting change point in the middle of a series []. The U statistic is calculated using the equation below. At the same time, critical values for the test statistic can be found in the table given by Buishand [] or using Monte Carlo simulation.

Example
A quick example of pyHomogeneity usage is given below.
import numpy as np
import pyhomogeneity as hg
# Data generation for analysis
data = np.random.rand(360,1)
result = hg.pettitt_test(data)
print(result)
Output is like this:
Pettitt_Test(h=False, cp=89, p=0.1428, U=3811.0, avg=mean(mu1=0.5487521427805625, mu2=0.46884198890609463))
Whereas, the output is a named tuple, so user can call by name for specific result:
print(result.cp)
print(result.avg.mu1)
or, user can directly unpack the results like this:
h, cp, p, U, mu = hg.pettitt_test(x, 0.05)
Users can plot results by following (Figure 1):
Homogeneity result plot.
mn = 0
mx = len(data)
loc = result.cp
mu1 = result.avg.mu1
mu2 = result.avg.mu2
plt.figure(figsize=(16,6))
plt.plot(data, label=”Observation”)
plt.hlines(mu1, xmin=mn, xmax=loc, linestyles=’--’, colors=’orange’,lw=1.5, label=’mu1 : ‘ + str(round(mu1,2)))
plt.hlines(mu2, xmin=loc, xmax=mx, linestyles=’--’, colors=’g’, lw=1.5, label=’mu2 : ‘ + str(round(mu2,2)))
plt.axvline(x=loc, linestyle=’-.’ , color=’red’, lw=1.5, label=’Change point : ‘+ str(loc) + ‘\n p-value : ‘ + str(result.p))
plt.title(‘Title’)
plt.xlabel(‘X’)
plt.ylabel(‘Y’)
plt.legend(loc=’upper right’)
plt.savefig(“F:/homogeneiry_results_plot.jpg”, dpi=600)
Users can find more examples in pyHomogeneity’s Github repository’s example section.
Quality control
Tests for pyHomogeneity package are performed using some fixed random data, where the results of those data are known. So, the performance of the functions is easily determined by comparing the output of the functions with the known results. Anyone can perform the unittest locally by using the below command in the root of the local copy of pyHomogeneity:
pytest –v
In addition, pyHomongeneity uses the continuous integration (CI) platform Travis CI for automatic testing after each change of the code base uploaded to the source repository []. The tests on Travis CI have been performed using different Python versions (2.7, 3.4., 3.5, 3.6, 3.7, 3.8) on Linux system. Users may raise issues on GitHub for additional support on using the package. Anyone can also contribute to this package. The contributor guideline can be found in the Contribution section on Github.
(2) Availability
Operating system
This package is platform independent, so it can be run on any operating system (GNU/Linux, Mac OSX, Windows) where python can be run.
Programming language
Python 2.7 and 3.4+
Additional system requirements
None
Dependencies
pyHomogeneity is written using core python packages. Only Numpy and Scipy are required to use it.
Software location
Archive
Name: Zenodo
Persistent identifier: http://doi.org/10.5281/zenodo.3785287
Licence: MIT
Publisher: Md. Manjurul Hussain Shourov
Version published: 1.1 and earlier versions. The DOI above always resolves to the latest version, previous versions can be identified with separate DOIs (see versions sections on the Zenodo repository page).
Date published: 04/05/2020
Code repository
Name: Github
Identifier: https://github.com/mmhs013/pyHomogeneity
Licence: MIT
Date published: 04/05/2020
Language
English
(3) Reuse potential
pyHomogeneity is a Python package, a widely used and freely available programming language. Because the package is for Python, it is platform-independent and therefore can be used by the majority of individuals in the data science community. It is a statistical analysis tool that performs different types of homogeneity tests for time series data. So, it can be used for data quality tests for study or academic research purposes. Many researchers have already started to use pyHomogeneity package in their research [, , , ].
Every function has docstrings to ensure clarity about what each function does and available options that the user can declare. The user documentation of pyHomogeneity is hosted on GitHub repository. The documentation contains some sample examples that can be easily modified for different user scenarios. pyHomogeneity is released under the MIT license and welcomes any contributions. We encourage users to submit feedback using GitHub issue tracker, or by emailing the authors.