



(1) Overview
Introduction
Mediation effect refers to the effect conveyed by an intervening variable (denoted as M) to an observed relationship between an exposure (X) and a response variable (Y) of interest, as shown in Figure 1. The intervening variable is often called a mediator. The research questions answered by mediation analysis are usually: 1) how much of the association between X and Y can be explained through the effect of X on M, and sequentially on Y; and 2) is there still direct association between X and Y after adjusting for the effects through M? For example, [] used the mediation analysis to explore factors that explain the racial disparities in three-year mortality rate among breast cancer patients. In the analysis, race was the exposure variable, the three-year mortality rate was the response. Mediators such as age at diagnosis, ER/PR status, and insurance type were identified that significantly explained the racial disparity, and those important mediators could fully explain the racial disparity. Both mediation and confounder effects refer to the indirect effects transmitted between X and Y. Although the explanations of these effects are different in that the mediator is a part of the causal path while confounder is not, mediation analysis can be used to make inferences on both mediation and confounder effects []. Hence, mediation analysis has been widely used in social sciences, psychological research, behavioral research, health prevention, epidemiological studies, and genetic analysis.
Mediation Diagram.
There are generally two settings for mediation analysis. One is based on linear models to assess the mediation effects. In this branch, there are usually three methods to test the mediation effect. The causal steps approach is used to establish mediation associations, while the product of coefficients [] and the difference of coefficients [] methods are used to quantify the mediation effects. [] conducted a series of simulation studies to compare these methods and concluded that when the relationships among mediators, exposure and response variables are fitted with linear regression models, the mediation effects measured by the above methods are equivalent. However, when the relationships among variables cannot be fitted with linear regression models, the methods which estimate the mediation effects directly based on the estimated coefficients of variables in linear models become inappropriate. For example, when the dependent variable or a mediator is binary and a logit regression model is used to estimate the coefficients, the scales of coefficients change in the models when different groups of variables are included as explanatory variables. In such situations, standardizing coefficients is required for mediation effects estimation. Moreover, separating indirect effects from multiple mediators is difficult since the effects measured through logit or probit models are not additive. Counterfactual framework is the other popular setting to implement mediation analysis [, , , ]. [] proposed the Potential Outcome model, which defined the causal effect as the difference between two potential outcomes if an individual could take different treatments without changing the potential outcomes – as if only one treatment were taken. Let Yi(X) denote the post-treatment potential outcome if subject i is exposed to X. To compare the change in outcome when the exposure changes from x to x∗ (e.g., from 0 to 1 for binary X), the causal effect of treatment on the response variable for subject i is defined as Yi(x) – Yi(x∗). It is usually impossible to estimate the individual causal effect since only one of the responses, Yi(x) or Yi(x∗), is observed. [] proposed, instead of estimating causal effect on a specific subject, to estimate the average causal effect over a pool of subjects: E(Yi(x) – Yi(x∗)). If the subjects are randomly assigned to control or treatment groups, the average causal effect equals the expected conditional causal effect, E(Yi|X = x) – E(Yi|X = x∗). Denote Mi(X) as the potential value of M when subject i is exposed to treatment X. Let Yi(x, m) be the potential outcome of subject i given X = x and M = m. The total effect of X on Y when X changes from x to x∗ is defined as Yi(x, Mi(x)) – Yi(x∗, Mi(x∗)). Conventional mediation analysis decomposes the total effect into direct effect from X and indirect effect through M. [] introduced the concepts controlled direct effect, defined as Yi(x, m) – Yi(x∗, m) and natural direct effect, defined as ζi(x) ≡ Yi(x, Mi(x∗)) – Yi(x∗, Mi(x∗)). Both direct effects measure the change in Y when X changes from x to x∗ while M is held fixed. The difference between controlled and natural direct effects is that the controlled direct effect is measured when M is fixed at m, a chosen constant; whereas to measure the natural direct effect, M is random as if the actual exposure were x∗. Consequently, the natural indirect effect is the difference between total effect and natural direct effect, δi(x) ≡ Yi(x, Mi(x)) – Yi(x, Mi(x∗)). In comparison, the difference between a total effect and a controlled direct effect cannot in general be interpreted as an indirect effect [, ]. A common restriction for definitions of controlled and natural direct effects is that the exposure levels, x and x∗, have to be preset. However, when the relationship among variables cannot be assumed linear, it is hard to choose representative exposure levels, especially if the exposure variable is multi-categorical or continuous.
[] proposed general definitions of mediation effects under the counterfactual framework. The derived mediation analysis is promising in that first, the mediation analysis is generalized so that we can deal with binary, multicategorical or continuous exposure, mediator and response variables. Second, the indirect effects contributed by multiple mediators of different types (continuous or categorical) are separable, which enables the comparison of relative mediation effects carried by different mediators. Third, in addition to linear models, general predictive models such as survival models and Multiple Additive Regression Trees (MART, []) can be used to model associations among variables so that mediation analysis is possible in complicated situations. The method is fully implemented in the R package mma, which is available from the Comprehensive R Archive Network (CRAN) at https://cran.r-project.org/web/packages/mma/index.html. Package mma is the first package that realized the algorithms and inherited the contributions by [, ]. Other R packages for mediation analysis focus on different aspects or are based on different methods of mediation analysis. The package mediation was built based on the methods proposed by [] and []. When doing mediation analysis based on generalized linear models, the two packages generate very similar results. The major contribution of the mma package is that in addition to generalized linear models, MART and natural splines can be used to fit the relationships among variables, based on which inferences on mediation effects can be made taking into consideration more complicated variable transformations and interactions without the necessity of pre-specifying them. Also, when MART is used, all missing data can be handled without losing information. For detailed description of MART and its advantages at model fitting, the readers are referred to [] and []. Furthermore, generic functions are created in mma to generate figures that help visually illustrate the mediation effects. In the mma package, the packages glm and gbm were used to fit generalized linear models or MART respectively.
Implementation and architecture
Methods
Notations
Let M = (M1, …, Mp)T, where Mj is the jth mediator/confounder. Z is the vector of other independent explanatory variables that are directly related with Y, but not with X. Let Y (x, m) be the potential outcome if the exposure X is at x, and M at m. Denote the domain of X as domX. Let u∗ be the infimum positive unit such that there is a biggest subset of domX, denoted as domX∗, in which any x also satisfies x + u∗ ∈ domX, and that domX = domX∗ ∪ {x + u∗|x ∈ domX∗}. If u∗ exists, it is unique. Figure 1 illustrate the relationships among variables.
Mediation Effects
The mediation effects include the total effect, direct effect from X, and indirect effect from X through M to Y. []define the mediation effects through the change rate in Y when X changes from x by a u∗ unit.
Definition 1 Given Z, the total effect (TE) of X on Y at X = x∗ is defined as the change rate in E(Y (X, Z)) when X changes by a u∗ unit:  . The average total effect is defined as ATE|Z = Ex∗[TE|Z(x∗)], where the density of x∗ is
. The average total effect is defined as ATE|Z = Ex∗[TE|Z(x∗)], where the density of x∗ is  .
.
Definition 2 For a given Z, the direct effect (DE) of X on Y not from Mj is defined as  , and the average direct effect of X on Y not from Mj is
, and the average direct effect of X on Y not from Mj is  , where M–j denotes the vector M without Mj.
, where M–j denotes the vector M without Mj.
The definition of direct effect not from Mj is analogous to the natural direct effect that allows for natural variation in the levels of the mediator between subjects. Instead of allowing Mj to vary conditionally on a fixed level of the predictor, we allow it to vary marginally.
Definition 3 Given Z, the indirect effect of X on Y through Mj is defined as  . Similarly, the average indirect effect through Mj is
. Similarly, the average indirect effect through Mj is  .
.
Compared with conventional definitions of the average mediation effect that focus on the differences in expected Y when X changes from x to x∗, we define mediation effect based on the rate of change so that the effect will not change with either the unit or the changing unit (x∗ – x) of X. Therefore, the definitions of mediation effects are generalized and consistent for exposure variables measured at any scale (binary, multicategorical or continuous).
Multiple Mediation Analysis with Non-/Semi-Parametric Predictive Models
When generalized linear models are used to fit the variable relationships, the mediation effects can be estimated based on the coefficients in the generalized linear models. The variances of the estimates can be calculated using Delta method. [] listed the estimates and variances of mediation effects based on various generalized linear models. When generalized linear regression is not sufficient to describe variable relationships, mediation analysis can be very difficult. The following algorithms that derived directly from the definitions of mediation effects provide a non-/semi-parametric method to calculate mediation effects. The mma package adopted the algorithms to calculate the mediation effects and make inferences.
The algorithm is based on the assumption that the relationships among mediators are that for the ith observation:
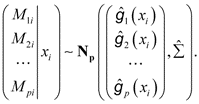
Also the fitted model for Y has the form

where ∈i is an independent random error term. The f can be any predictive models. In the package mma, MART and generalized linear models (GLM) are adapted. The mean of Mki is estimated individually by ĝk (xi). ĝ are the functions to model the relationships between X and M. Smoothing splines and GLM are used in the package mma to build ĝ. The variance-covariance matrix  is estimated through the residuals Mki – ĝk(xi). When the kth mediator, Mk, is categorical with K categories, ĝk is a vector of k – 1 elements, where each element gives the estimated probability of one category except for the reference group. [] described the details to construct .
is estimated through the residuals Mki – ĝk(xi). When the kth mediator, Mk, is categorical with K categories, ĝk is a vector of k – 1 elements, where each element gives the estimated probability of one category except for the reference group. [] described the details to construct .
Denote the observations (yi, xi, M1i, …, Mpi), i = 1, …, n. Let a be the change unit of X at which we would like to test the change in Y. The a can be set at u∗ if it is positive. For continuous X where u∗ is zero, we may set a = 1. Let Dx = {xi|xi + a ∈ domX, i = 1, …, n} and N be a large number.
Algorithm 1.Estimate the total effect:
- Sample N xs from Dx with replacement, denote as {xj, j = 1, …, N}.
- Generate (M1j1, …, Mpj1)T given X = xj from equation (1) for j = 1, …, N.
- Generate (M1j2, …, Mpj2)T given X = xj + a from equation (1) for j = 1, …, N.
-
 .
.
If X is a binary variable, we can either calculate E(Y|x = 1) – E(Y|x = 0) directly from the observations, or make xj = 0 and a = 1 for all js, and continue with step 2 above. When the mediator Mk is categorical, generations from equation [1] give the probability vector of Mk belonging to each group, based on which Mk is drawn with a multinomial distribution.
Algorithm 2.Estimate the direct effect not through Mk:
- Use the samples generated by Steps 1 to 3 of Algorithm 1.
- Combine the vectors
 and
and  and randomly permute the combined vector, denote the new vector as
and randomly permute the combined vector, denote the new vector as  . forms a sample of Mk from its marginal distribution.
. forms a sample of Mk from its marginal distribution. -
 is estimated by
is estimated by
Due to the randomness brought in by sampling, the two algorithms are repeated more than once, and the average results from the repetitions are the estimate of the mediation effects. The two algorithms are realized by the function med to estimate the mediation effects. Furthermore, the bootstrap method is used in functions mma and boot.med to make inferences on the estimated mediation effects. Bootstrap samples are drawn from  , and then Algorithms 1 and 2 are used on the bootstrap samples to form estimates.
, and then Algorithms 1 and 2 are used on the bootstrap samples to form estimates.
Use of package mma
The proposed mediation analysis consists of three steps which are completed by three functions: function data.org is used to identify potential mediators and to transform the data sets into the analytic format; function med is used to estimate the mediation effects based on the whole data set; and function boot.med is for making inferences on mediation effects using the bootstrap method. The function mma does all three steps together. Other functions are generic functions print, summary and plot to help present results of analysis. All arguments used in the functions are fully documented within the package.
The package also includes a real data set Weight_Behavior. This data set was collected by Dr. Scribner from the Louisiana State University Health Sciences Center to explore the relationship between children’s weight (measured by a continuous variable bmi and a binary variable overweight) and behavior (such as snack, sports, computer hours, etc.) through a survey of children, teachers and parents in Grenada in 2014. This data set has 691 observations and 15 variables. Table 1 lists the format and descriptions of variables. We use the data set to illustrate the use of package mma. The illustration is based on the package mma version 3.1 – 0 or later.
Table 1
Variables in data set “Weight_Behavior”.
| Variable Name | Description |
|---|---|
| bmi | Body mass index |
| age | Age at survey |
| sex | Male or female |
| race | African American, Caucasian, Indian, Mixed or Other |
| numpeople | Number of people in family |
| car | Number of cars in family |
| gotosch | Four levels of methods to go to school |
| snack | Eat a snack in a day or not |
| tvhours | Number of hours watching TV per week |
| cmpthours | Number of hours using computer per week |
| cellhours | Number of hours playing with cell phones per week |
| sports | In a sport team or not |
| exercise | Number of hours of exercises per week |
| sweat | Number of hours of sweat-producing activities per week |
| overweigh | The child is overweight or not |
Identify Mediators
The function data.org is used to identify mediators. To be identified as a mediator, a variable must satisfy two conditions. First, the variable is significantly correlated with the predictor. To test this, we use chi-square test, ANOVA, or the Pearson’s correlation coefficient tests, depending on the variable types of the predictor and the potential mediator. The significance level is set by the argument alpha2 (0.1 by default). The second condition is that the variable is significantly related with the outcome, given that all other related factors are included in the model. The significance level for this test is set by alpha (0.1 by default). If both conditions are satisfied, the variable will be included in the data set as a mediator. If only the second condition is satisfied, the variable is included as a covariate but not a mediator, unless the variable is specified by jointm. The argument jointm is used in functions to specify the group(s) of variables where the joint effect of all variables in a group is of interest. jointm is a list where the first element tells the number of groups, and each of the following items identifies a group of variables to be considered jointly. A variable can be shown in more than one group. If a variable is listed in the jointm argument, it is forced into the model as a mediator. If the variable has not been specified by jointm and the second condition is not satisfied, the variable is excluded from further analysis. If a researcher wants to check the individual mediation effect of one or more variables even if the variables do not meet the above two conditions, the trick is to form a group of those variables in jointm. Hence, both the individual and joint mediation effects of the group will be reported.
The result of data.org is classified as “med_iden” class. The generic function summary was created to show the test results and the identified lists of mediators and covariates.
The following codes are to identify mediators and covariates that explain the sexual difference in being overweight in the data set weight_behavior. In this example, the outcome is the binary variable overweight (1 for yes and 0 for no) and the predictor is sex. The potential mediators are continuous variables tvhours, cmpthours, cell-hours, exercise, and sweat; binary variables sports and snack; and multi-categorical variable gotosch. Also we are interested to see the joint mediation effects of TV, computer, and cellphone hours. In the following codes, x is the dataset that includes the predictor, and all potential mediators and covariates. The argument pred identifies the predictor by specifying its column number or variable name in x. If the predictor is binary, the argument predref can be used to specify the reference group. If not specified, the first of the ordered groups will be the reference group. The argument mediator identifies all potential mediators in x. The variables are identified as binary or categorical if they are factors, characters, or has only 2 levels. Alternatively, a binary or categorical mediator can be identified by listing it under the argument binmed or catmed and the reference group be designated by the corresponding argument binref or catref. Any variables in x that are not identified as potential mediators or predictor by mediator or pred are included in further analysis as covariates, Z, without being tested.
R> data(“weight_behavior”)
> x=weight_behavior[,2:14]
> y=weight_behavior[,15]
> data.bin<-data.org(x,y,pred=2,mediator=c(1,3:13),
+ jointm=list(n=1,j1=c
+ (“tvhours”,“cmpthours”,
+ “cellhours”)), predref=“M”,
+ alpha=0.4,alpha2=0.4)
> summary(data.bin)
Identified as mediators:
[] “tvhours” “cmpthours” “cellhours” “exercise”
“sweat” “sports”
Selected as covariates:
[] “car”
Tests:
P-Value 1 P-Value 2
age 0.886 NA
sex 0.176 NA
race 0.866 NA
numpeople 0.587 NA
car 0.061 0.496
gotosch 0.703 NA
snack 0.687 NA
tvhours - 0.801 0.484
cmpthours - 0.878 0.760
cellhours - 0.078 0.688
sports * 0.000 0.004
exercise * 0.192 0.268
sweat * 0.142 0.046
----
*:mediator,-:joint mediator
P-Value 1:Type-3 tests in the full model
P-Value 2:Tests of relationship with the Predictor
The function data.org creates a list, where x gives a data set that includes all identified mediators and covariates in explaining the outcome; dirx tells the position of predictor in x; contm, binm, catm and jointm specify the positions of continuous, binary, categorical, and joint mediators in x. Any variables in x but not identified as mediators are the covariates that can be used to explain the outcome. In the above code, the variables “tvhours”, “cmpthours”, “cellhours”, “exercise”, “sweat”, and “sports” are identified as mediators, among which “tvhours”, “cmpthours”, and “cellhours” are forced in as mediators since their joint mediation effect is of interest.
Point Estimates of Mediation Effects
The output from data.org can be directly used by the function med for mediation analysis. Using the above example, the following codes do a mediation analysis on the data sets with identified mediator and covariates. Two modeling methods were used for modeling relationship among variables: generalized linear model as in med1 and nonlinear method (MART and Smoothing Splines) by setting nonlinear=T as in med2.
> med1<-med(data=data.bin,n=100,seed=1)
> med2<-med(data=data.bin,n=100,seed=1,
nonlinear=TRUE)
In the above codes, algorithms are repeated 100 times (set by n = 100) to account for the randomness brought in by the sampling process. The argument seed=1 is set so the results are repeatable. The result for the med function is a “med” class. A generic function was generated to show the estimated mediation effects.
For both models, the response variable is on the scale of log-odds of being overweight. The mediation effects calculated by the logit model or MART are not exactly the same but close. The main reason is that MART considers nonlinear relationships, while the logit model assumes a linear relationship between variables and the response. Also note that the sum of direct and indirect effects may not equal the total effects. This is because there are potential correlation and there- fore overlapping mediation effects among mediators. If one would like to assume independent mediation effects, calculating the total effect by adding up the direct and indirect effects is preferred. Based on MART, overall, girls are more likely to be overweight than boys (the total effect is 0.14>0). That is on average, the odds of being overweight for girls is exp(0.14) = 1.15 times that for boys, when all covariates are controlled, while the mediators can change between the girl and the boy groups. The joint mediation effects of TV, computer, and cell phone hours on the sexual difference in the log-odds of being overweight is 0.014, meaning that 0.014/0.14 = 10% of the sexual difference in overweight can be explained by the joint effects of weekly hours spent on TVs, computers, and/or cellphones. A potential explanation is that, on average, girls spend more time on TV, computers, and cellphones; and the amount of time spent on those activities is positively related with being overweight. The explanation may be visually shown by the plot function, which will be illustrated in the Results section.
> med1
The estimated total effect: 0.5626
The estimated indirect effect:
all tvhours cmpthours cellhours exercises sweat sports j1
0.1928 -0.0119 0.0092 0.0160 -0.0081 0.0110 0.1579 0.0162
> med2
The estimated total effect: 0.1418
The estimated indirect effect:
all tvhours cmpthours cellhours exercises sweat sports j1
0.0917 0.0028 0.0068 0.0045 -0.0001 0.0029 0.0784 0.0135
Statistical Inferences on Mediation Effects
We use the bootstrap method to measure the uncertainty in estimating the mediation effects. The following codes are used to calculate the variances and confidence intervals of the estimated mediation effects. The argument weight is a vector that assigns weights to observations when the observations are not treated equally in the analysis. For the bootstrap samples, the observations are drawn from the original data set with replacement and with probabilities proportional to “weight”. n2 indicates the number of bootstrap iterations. The mediation effects, variances, and confidence intervals are estimated based on the estimated mediation effects from bootstrap samples.
> med1.boot<-boot.med(data=data.bin,n=100,n2=500,
seed=1)
> med2.boot<-boot.med(data=data.bin,n=100,n2=500,
seed=1,nonlinear=TRUE)
The results from the bootstrap functions are classed as “mma”. Generic functions “print”, “summary”, and “plot” are generated for the class to help users interpret the results easily. This will be shown in the Results section.
Finally, the whole process, from identifying mediators to estimating and making inferences on the mediation effects, can be carried out by the function mma, as shown by the following codes. If any manual intervention is required, separate functions are recommended.
R>mma1<-mma(x,y,pred=2,mediator=c(1,3:13),
+ jointm=list(n=1,j1=c(“tvhours”,
“cmpthours”,“cellhours”)),
+ predref=“M”,alpha=0.4,alpha2=0.4,n=20,
n2=100,seed=1)
>mma2<-mma(x,y,pred=2,mediator=c(1,3:13),
+ jointm=list(n=1,j1=c(“tvhours”,
“cmpthours”, “cellhours”)),
+ predref=“M”,alpha=0.4,alpha2=0.4,n=20,
n2=100,seed=1,nonlinear=T)
The output from the mma function is assigned an “mma” class. Therefore, the corresponding generic functions can be used. In all functions, if the outcome is a continuous variable and MART is used to model the relationship, the default distribution is “gaussian”. If a generalized linear model is used to model the relationship, the default family is gaussian(link=“identity”). Similarly, if the outcome is binary, the default distribution for MART is “bernoulli”, and the default family for generalized linear models is binomial(link = “logit”). The distribution and family can be changed by assigning a different value to the argument distn or family1 respectively.
If the predictor is continuous, the default margin (“a” in Algorithms 1 and 2) is 1. It can be changed by setting margin. If the mediation effects on a new set of predictors are of interest, one can set x.new in the functions.
In general, the function mma runs faster when generalized linear model is used. In the above functions, the results for mma1 were obtained in about three minutes and for mma2, it took about 12 minutes.
Results
Outputs from the functions boot.med, and mma are given the class “mma”. In this section, we use the output stored in mma2 to illustrate the generic functions. The summary function gives the estimation of mediation effects by using the whole data set (est) or by averaging the estimates from bootstrap samples (mean). It also calculate the estimated standard deviations (sd) and confidence intervals of the mediations effects from bootstrap samples. Two methods are used to build the confidence intervals: normal approximation, (upbd, lwbd), and quartiles of bootstrap estimates (lwbd_q, upbd_q). If RE is set as “TRUE”, summary will also report the summaries of the relative effects, calculated as the “(in)direct effect/total effect”. When plot=T, by default, the summary function will plot the estimated relative effects and their confidence intervals (Figure 2). The significance level can be set using the argument alpha, which is 0.05 by default.
Output from summary (mma).
Using the quantile confidence interval, summary shows that at the significance level 0.2, only “sports” has a significant indirect effects on the sexual difference in overweight, which explains about 57% (22%, 89%) of the sexual difference. After accounting for all the factors, about 24% of the sexual difference still cannot be explained.
The plot function helps illustrate the indirect effects of the mediators by showing the relationship between the mediator and the outcome after accounting for other variables. The plot also shows how the predictor relates to the mediator. If the predictor is continuous, the fitted relationship between the predictor and the mediator is plotted. Otherwise, the distributions of the mediator at different levels of the predictor are graphed. The mediator is specified by the argument vari, which can be the column number or the name of the mediator. We can also change the range of the mediator by setting the argument xlim. The following codes illustrate how the binary mediator sports mediates the sexual difference in overweight.
> summary(mma2,RE=T,alpha=0.2)
MMA Analysis: Estimated Mediation Effects Using MART
indirect.effect
all tvhours cmpthours cellhours exercise sweat sports j1
est 0.078 -0.008 -0.001 -0.005 0.000 -0.008 0.060 0.008
mean 0.147 0.011 0.016 0.010 0.003 0.002 0.118 0.031
sd 0.063 0.016 0.027 0.023 0.025 0.017 0.049 0.035
upbd 0.228 0.031 0.050 0.040 0.034 0.024 0.180 0.076
lwbd 0.065 -0.010 -0.019 -0.020 -0.028 -0.019 0.056 -0.014
upbd_q 0.227 0.028 0.049 0.041 0.034 0.024 0.194 0.084
lwbd_q 0.063 -0.011 -0.015 -0.019 -0.023 -0.020 0.057 -0.011
total.effect
est mean sd upbd lwbd upbd.90% lwbd.10%
0.102 0.290 0.169 0.506 0.073 0.519 0.085
direct.effect
est mean sd upbd lwbd upbd.90% lwbd.10%
0.024 0.143 0.147 0.332 -0.045 0.379 0.001
The relative effects:
indirect.effect
all tvhours cmpthours cellhours exercise sweat sports j1
est 0.760 -0.078 -0.013 -0.049 0.005 -0.075 0.586 0.083
mean 0.655 0.055 0.009 0.049 -0.016 0.013 0.569 0.094
sd 0.498 0.139 0.328 0.239 0.271 0.127 0.566 0.147
upbd 1.293 0.233 0.429 0.355 0.332 0.177 1.295 0.282
lwbd 0.016 -0.123 -0.411 -0.258 -0.363 -0.150 -0.156 -0.094
upbd_q 0.994 0.148 0.162 0.142 0.140 0.100 0.893 0.301
lwbd_q 0.292 -0.055 -0.084 -0.091 -0.140 -0.107 0.215 -0.072
direct.effect
est mean sd upbd lwbd upbd.90% lwbd.10%
0.024 0.345 0.498 0.984 -0.293 0.708 0.006
>plot(mma2,vari=“sports”)
By the top plot of Figure 3, on average, children who did not participate on a sport team (sports = 0) were less likely to be overweight than those participated in a team (predicted probability of being overweight is about 0.07 and 0.105 respectively). The middle plot shows the proportion of girls in sport teams is about 45%, which is larger than the proportion of boys, about 35% as shown in the bottom plot of Figure 3. Figure 4 shows the relationship between overweight and exercise, and between sex and exercise. The fitted relationship between overweight and exercise is not linear since an MART was used to model the relationship.
Output from plot(mma) on “sports”.
Output from plot(mma) on “exercise”.
Quality control
All the functions of mma were tested to see they produce the desired results by comparing outputs from the package and other statistical programs. The structure of the package successfully passed the CRAN R CMD check and the results from this check can be found on CRAN.
(2) Availability
Operating system
The package can work with either Windows, Mac OS X or Linux.
Programming language
R version 2.14.1 or higher.
Additional system requirements
An Internet connection is required to install the mma package.
Dependencies
R packages: gbm, car, gplots, splines, and survival.
List of contributors
This package was created by Drs. Qingzhao Yu and Bin Li.
Software location
Archive
Name: CRAN
Persistent identifier:https://cran.r-project.org/web/packages/mma/index.html
Licence: GPL2
Version published: 4.0 – 0
Date published: 12/12/2016
Code repository (e.g. SourceForge, GitHub etc.) (required)
Name: CRAN
Persistent identifier:https://cran.r-project.org/web/packages/mma/index.html
Licence: GPL2
Date published: 12/12/2016
Language
R
(3) Reuse potential
Package mma is an R package that provides mediation analysis using general linear or nonlinear predictive models to fit relationships among variables. The analysis method in mma is a general extension of mediation analysis under the counterfactual framework. The method generalizes and improves the existing mediation analysis methodologies in many ways. First, responses, exposure variables and mediators can be measured at any scale: continuous, binary or multicategorical. Second, multiple mediators of different types are allowed in the pathway analysis simultaneously. Indirect effects transmitted by an individual mediator can be differentiated from the total effect, permitting the comparison of the importance of the mediators. Third, the mediation study allows correlations among mediators. Mediation effects from joint mediators can be estimated. Finally, the concepts of mediation analysis can be applied with nonlinear modeling such as MART.
The mediation analysis can be extended to the survival model and/or multilevel contexts. [] has extended the method to additive survival models. The package mlma expanded the method to multilevel models where the mediators can be of different levels in a hierarchical model.
One limitation of mma is that generalized linear models were used to test the independence between variables and outcome. Therefore, linear relationships are assumed to identify mediators and covariates. The assumption should be relaxed in the future by adapting the roughness of the concomitant rank test [], a nonparametric method, to test the independence among variables.